First Experiment with Scrapy
I have not done much web scraping since playing around with BeautifulSoup many years ago. Back then, I felt BSoup was a great tool but needed a deeper understanding of the HTML tags and CSS selectors to make good use of the tool. There were just so many more interesting topics in Python that pushed web scraping down the priority list.
Fast forward a few years, I started to get deeper into web development with Django. I am still a beginner, but HTML and CSS no longer intimidate me the way it did before. When listening to TalkPython Episode #283: Web scraping, the 2020 edition, the Scrapy, and the Scrapinghub projects seem like two good projects that can make web scraping scalable. I decided to give Scrapy a shot, I am jogging down the experience in order to keep some progress notes and perhaps it can help other people.
The example I used was taken straight from the https://scrapy.org/ site:
Just to be sure, I went to the https://blog.scrapinghub.com site to look for the CSS classes indicated in the script.
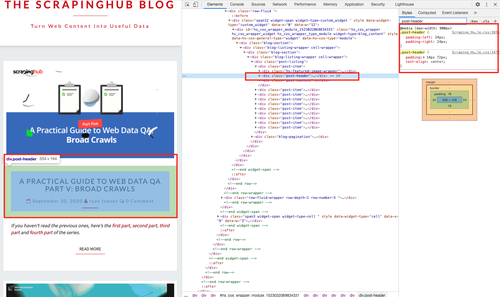
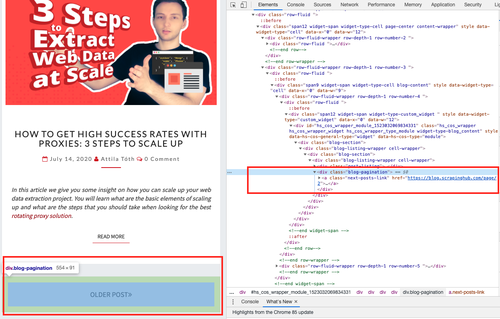
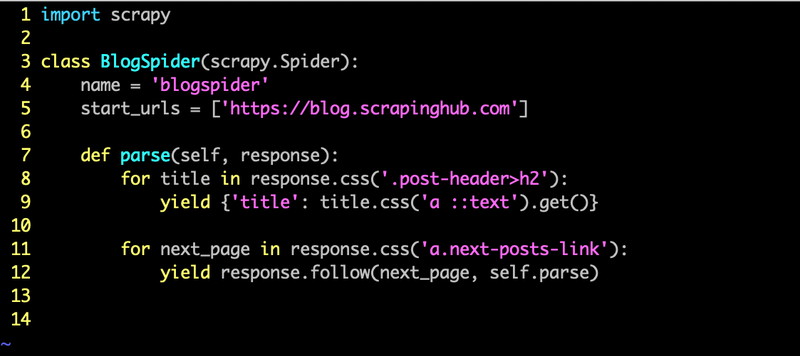
I like how readable the script it, I can see that we were looking for the h2 tag below the post-header CSS class and following the 'next-posts-link' CSS selector. What is also nice is the function are Python generators that yield results as they come in.
$ scrapy runspider blog_spider.py
2020-10-04 16:16:09 [scrapy.utils.log] INFO: Scrapy 2.3.0 started (bot: scrapybot)
2020-10-04 16:16:09 [scrapy.utils.log] INFO: Versions: lxml 4.5.2.0, libxml2 2.9.10, cssselect 1.1.0, parsel 1.6.0, w3lib 1.22.0, Twisted 20.3.0, Python 3.8.1 (v3.8.1:1b293b6006, Dec 18 2019, 14:08:53) - [Clang 6.0 (clang-600.0.57)], pyOpenSSL 19.1.0 (OpenSSL 1.1.1h 22 Sep 2020), cryptography 3.1.1, Platform macOS-10.15.6-x86_64-i386-64bit
2020-10-04 16:16:09 [scrapy.utils.log] DEBUG: Using reactor: twisted.internet.selectreactor.SelectReactor
2020-10-04 16:16:09 [scrapy.crawler] INFO: Overridden settings:
{'SPIDER_LOADER_WARN_ONLY': True}
2020-10-04 16:16:09 [scrapy.extensions.telnet] INFO: Telnet Password: d5084a64716db6d3
2020-10-04 16:16:09 [scrapy.middleware] INFO: Enabled extensions:
['scrapy.extensions.corestats.CoreStats',
'scrapy.extensions.telnet.TelnetConsole',
'scrapy.extensions.memusage.MemoryUsage',
'scrapy.extensions.logstats.LogStats']
2020-10-04 16:16:09 [scrapy.middleware] INFO: Enabled downloader middlewares:
['scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware',
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware',
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware',
'scrapy.downloadermiddlewares.retry.RetryMiddleware',
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware',
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware',
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware',
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware',
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware',
'scrapy.downloadermiddlewares.stats.DownloaderStats']
<skip>
According to the doc https://docs.scrapy.org/en/latest/intro/overview.html, what we wrote is a Spider definition for the Scrapy crawler engine. It begin by making requests to the URLs in start_urls and called the default callback method parse. From the output, we can see that the requests are made asynchronously using the Twisted framework. This is a good start to picking up web crawling again, I am looking forward to experiment with more use cases that can automate some of my daily tasks.
Hope everybody is staying safe and being productive.
Happy Coding!
Eric